Los flujos de datos corresponden a la reutilización de distintos queries o consultas, que han sido amoldados a los requerimientos de análisis. Pero, su gran ventaja es que se residen en la nube de Azure. Esto implica, que podemos reutilizar; y esta palabra es importante, vuelvo y repito: reutilizar lo que previamente hemos estructurado.
Ahora bien, en la siguiente esquemática nos encontramos en la parte inferior izquierda.
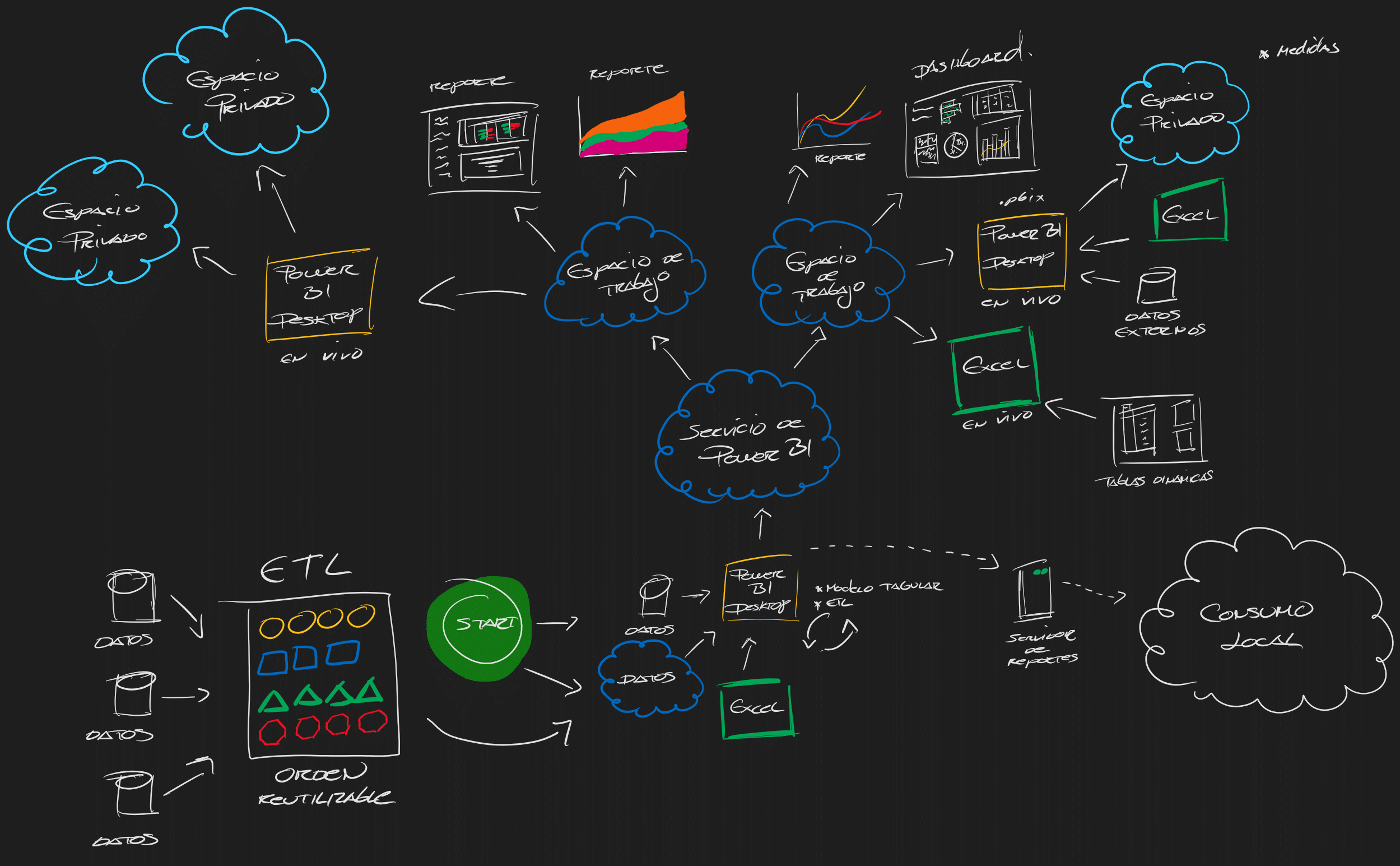
Solucionando el problema del ETL de autoservicio
Como ustedes sabrán, en Power BI Desktop tenemos a disposición a Power Query, siendo el motor de mezcla o mashup de datos. Allí, combinamos, transformamos, ordenamos, y todo lo que se nos ocurra que será necesario indexar posteriormente al modelo tabular.
Sin embargo, existe un pequeño gran inconveniente.
¿Qué sucede si quisiera compartir todo el proceso de ELT en una organización?[1]
Aquí es donde comienzan a brillar los flujos de datos, porque todos los pasos aplicados en Power Query, también conocido por su lenguaje llamado «M», se encuentran atados al archivo .pbix del modelo.
Esto quiere decir que, si quisiéramos darle la oportunidad a otras personas dentro de una compañía, de acceder al mismo grado de modificación de queries (entendiéndose que esto puede convertirse en algo complejo), tendríamos que copiar y pegar cada cambio en cada uno de los modelos.
Siendo operacional y productivamente inaceptable[2].
De la raíz a las extremidades
Con flujos de datos, -que al final es un sabor que contiene características más avanzadas de Power Query-; pero en la nube. Al estar disponible en el Servicio de Power BI, podemos conectarnos a una serie de tablas que hayan sido trabajadas, y luego, independientemente de sus próximas iteraciones o llamémosle; mejoras, automáticamente los usuarios que las utilicen en sus modelos analíticos podrán acceder a esos cambios con la capacidad de seguir manipulando (modificando) las tablas provistas desde los flujos de datos, y ajustarlas a sus requerimientos individuales.
En consecuencia, llevaremos a cabo un flujo de desarrollo en el que su despliegue no estará sujeto a la modificación individual de sintaxis o funciones en archivos individuales; sino de queries en la nube, permitiéndonos mantener un cordón umbilical y aprovechar las bondades que ofrece la automatización de procesos.
Podríamos explicar la rigidez en la raíz y la flexibilidad en las extremidades de la siguiente forma:
Tendrás acceso a las condiciones mínimas exigidas para analizar datos de grado organizacional sin limitar el grado de acción de tus requerimientos personales.
Explicación del esquema (4:56 minutos)
Recomiendo leer:
Esquemática: DirectQuery sobre Datasets en Power BI y Azure Analysis Services
[1] En la analítica de autoservicio, los procesos de ETL pueden seguir siendo necesarios en etapas posteriores al ingreso de datos desde procesos de grado empresarial. [2] Sin haber mencionado el aspecto de consumo de recursos y de variabilidad de los resultados por mantener múltiples procesos no estandarizados de ETL por parte de los usuarios finales.
El contenido esta genial!
¡Gracias! la recomendación que me distes de la tableta digitalizadora para explicar procesos de despliegue ha sido genial. Un gran abrazo.